Large Language Models(LLM)のメリットとデメリット: 深い洞察と具体例
イントロダクション
大規模な言語モデル(Large Language Models、LLM)は、近年AI分野で急速に注目を集めており、多くの業界で様々な応用が期待されています。しかし、その強力な機能とともに、一定のデメリットも存在します。この記事では、LLMのメリットとデメリットに焦点を当て、具体例を通じてそれらの特徴を理解していきましょう。
メリット
1. 高い精度の自然言語処理
LLMは、大量のテキストデータを学習することで、文章生成やテキスト分析などのタスクで高い精度を達成します。これにより、機械翻訳やチャットボットなどのアプリケーションで優れた性能が発揮されます。
2. ゼロショット学習
一部のLLMは、特定のタスクに対する訓練なしに、そのタスクを高い精度で実行できます。これにより、新しいタスクに対応するための学習コストが大幅に削減されます。
3. 文脈理解力
LLMは、関連する情報や状況に基づいて適切な答えを導き出す能力を持っています。これにより、状況に応じた個別のソリューションを提供することができます。
デメリット
1. 計算リソースとコスト
LLMの学習には、大量の計算リソースと高いコストがかかります。 これは、一部の研究者や企業にしか利用できない状況を生んでいます。
2. 倫理的問題
LLMは、学習データ中のバイアスや偏見を引き継ぐ可能性があります。これにより、不適切な言語生成や、特定のグループに対する不利益を引き起こすことがあります。
3. 信頼性の欠如
LLMが生成するテキストは、必ずしも真実や正確さを反映しているわけではありません。そのため、LLMの出力に依存しすぎることはリスクが伴います。
具体例
メリットの例: GPT-3
OpenAIが開発したGPT-3は、高い自然言語処理能力を持つLLMの代表例です。GPT-3は、文章生成や質問応答、code生成など幅広いタスクにおいて優れた性能を発揮します。
デメリットの例: バイアス
LLMが、特定の性別や人種に対するステレオタイプな表現を生成することが報告されています。
デメリットの例: ニュースのフェイク生成
大規模な言語モデルは、リアルタイムのニュース記事を生成する能力がありますが、それらが必ずしも事実に基づいているわけではありません。悪意を持った利用者により、フェイクニュースが拡散される可能性があります。
メリットの例: AIチャットボット
顧客対応やFAQのようなタスクにおいて、LLMを活用したチャットボットは効率的かつ円滑なコミュニケーションを提供します。これにより、企業のカスタマーサポートが整理され、顧客満足度も向上します。
デメリットの例: 自動生成された悪質なコンテンツの拡散
LLMを悪用すれば、煽るような記事や不適切な内容を大量に生成し、インターネット上に拡散させることができます。これによって、インターネット上の情報の信頼性が低下し、人々の感情に悪影響を与える可能性があります。
まとめ
大規模言語モデル(LLM)は、自然言語処理において画期的な成果をもたらし、多くの業界に革命的な影響を与えています。しかし、その高い性能とともに、いくつかのデメリットもあります。LLMの恩恵を受けるためには、適切な使い方と問題への注意が必要です。
将来的には、LLMを利用する際のガイドラインやルールが整備されることで、より安全で有益な技術として発展していくことが期待されます。
本題 いかがでしたでしょうか。以上はほぼすべてGPT-4が書いた文章です。 LLMがLLMの文章を書くとかエモいですね。 それでは。
Cool Japan Diffusion 2.1.1 の取扱説明書

はじめに
本記事では、2023/1/14に公開した画像生成AI、Cool Japan Diffusion 2.1.1 の取り扱い方について説明します。 まず、デモの使い方を説明します。 次に本格的に使うために、インストール方法をざっくり説明します。 その後、使い方の説明、特にプロンプトのテンプレートを説明します。 最後に、クリエイターの方々へ、ユーザの方々へメッセージをお送りします。
デモの使い方
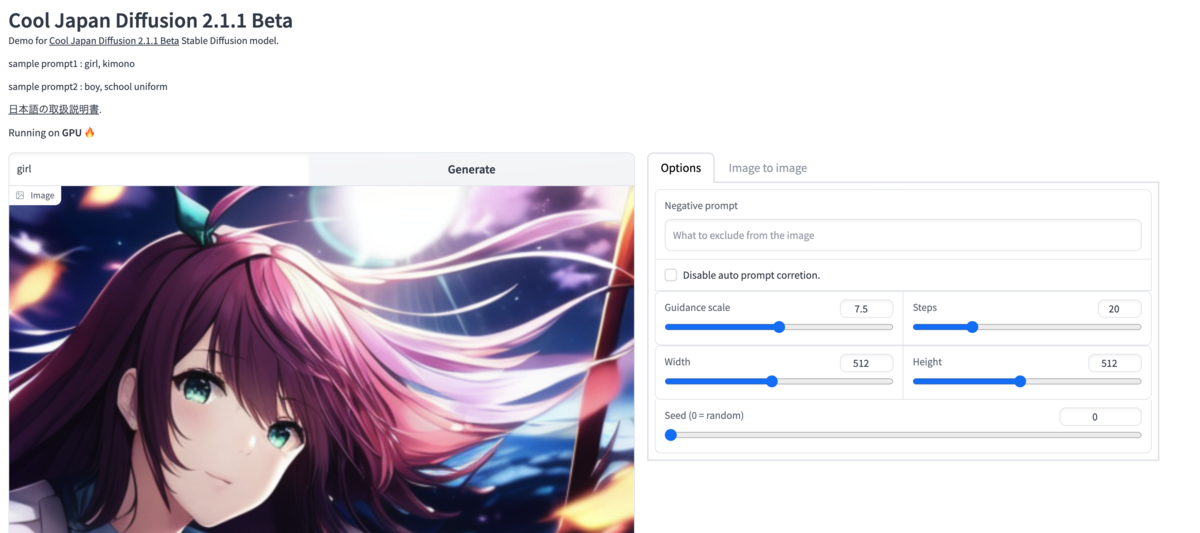
Hugging Face上でデモを行っているので、そちらを使うのが楽です。 テキスト欄にgirlやboyなどを入力して生成してみてください。 (詳細は後日)
インストール方法
基本的には、Web UIを想定しています。 ほとんど、Cool Japan Diffusion 2.1.1 Beta と変わらないため、 こちらの記事を参考にすると良いかもしれません。 Safetensors形式にも対応したので、安全性が気になる人はこちらを使ってください。
本格的な使い方
パソコンからWeb UIのアドレスにアクセスしてください。 パソコンでは次のような画面が出てきます。

Text-to-Imageの使い方
Text-to-Imageを使うと、文章から画像を生成することができます。この文章のことをプロンプトといいます。また、生成される画像の中に含まれてほしくない文章をネガティブプロンプトといいます。 Cool Japan Diffusionのプロンプト形式はNovel AI Diffusionなどとは全く違います。 これは研究用途以外には倫理的問題のあるデータセットであるDanbooruデータセットを含んでいないためです。 Cool Japan Diffusionのプロンプト形式は通常のStable Diffusionと同じものだと考えてください。このため、他のモデルやサービスと違って手軽さはありません。 一方で、基本的には形式に従って入力すれば、かんたんに出力することができます。 形式に従う必要はありませんが、手軽に楽しむためには形式をコピー・アンド・ペーストすることをおすすめします。
Cool Japan Diffusionでは、日本の文化、クールジャパンを(イラストを含む)アニメ、マンガ、ゲームの3種類で大まかに分類して生成することができます。 まず、それぞれの例を紹介します。

prompt: anime, a portrait of a girl with blue short hair and red eyes, official art, 4k, detailed
negative prompt: (((deformed))), blurry, ((((bad anatomy)))), bad pupil, disfigured, poorly drawn face, mutation, mutated, (extra limb), (ugly), (poorly drawn hands), bad hands, fused fingers, messy drawing, broken legs censor, low quality, (mutated hands and fingers:1.5), (long body :1.3), (mutation, poorly drawn :1.2), ((bad eyes)), ui, error, missing fingers, fused fingers, one hand with more than 5 fingers, one hand with less than 5 fingers, one hand with more than 5 digit, one hand with less than 5 digit, extra digit, fewer digits, fused digit, missing digit, bad digit, liquid digit, long body, uncoordinated body, unnatural body, lowres, jpeg artifacts, 2d, 3d, cg, text

prompt: manga, black and white manga style, shojo manga, a close up of a cool girl, official artwork, award winning manga style, 4k, detailed
negative prompt: (((deformed))), blurry, ((((bad anatomy)))), bad pupil, disfigured, poorly drawn face, mutation, mutated, (extra limb), (ugly), (poorly drawn hands), bad hands, fused fingers, messy drawing, broken legs censor, low quality, (mutated hands and fingers:1.5), (long body :1.3), (mutation, poorly drawn :1.2), ((bad eyes)), ui, error, missing fingers, fused fingers, one hand with more than 5 fingers, one hand with less than 5 fingers, one hand with more than 5 digit, one hand with less than 5 digit, extra digit, fewer digits, fused digit, missing digit, bad digit, liquid digit, long body, uncoordinated body, unnatural body, lowres, jpeg artifacts, 2d, 3d, cg, text

prompt: game, final fantasy 15, elden ring, close up of a dragon, 4k, 8k, highly detailed
negative prompt: (((deformed))), blurry, ((((bad anatomy)))), bad pupil, disfigured, poorly drawn face, mutation, mutated, (extra limb), (ugly), (poorly drawn hands), bad hands, fused fingers, messy drawing, broken legs censor, low quality, (mutated hands and fingers:1.5), (long body :1.3), (mutation, poorly drawn :1.2), ((bad eyes)), ui, error, missing fingers, fused fingers, one hand with more than 5 fingers, one hand with less than 5 fingers, one hand with more than 5 digit, one hand with less than 5 digit, extra digit, fewer digits, fused digit, missing digit, bad digit, liquid digit, long body, uncoordinated body, unnatural body, lowres, jpeg artifacts, 2d, 3d, cg, text
このようにプロンプトは長いですが、このプロンプトをベースに微妙に修正するだけでいろいろなバリエーションを生むことができます。
Cool Japan Diffusionのプロンプトは次のような形式をとっています。
クールジャパンの種類, 画風(作家名、作品名), 描写したい内容, フレーバーテキスト
例として具体的なプロンプトに当てはめてみます。
game(クールジャパンの種類), final fantasy 15, elden ring, (画風)close up of a dragon,(描写したい内容) 4k, 8k, highly detailed(フレーバーテキスト)
大まかにはこのような形式でいろんな画像を生成できます。なお、画風はなくても構いません。 付録に形式に使えるフレーズをまとめましたので、参考に使ってください。 ただし、画風に作品名や作家名を入れた場合、著作権を侵害するおそれがあることから、2つ以上混ぜたりしてください。 作品名や作家名はチートコマンドのようなものだと思ってください。
Image-to-Imageの使い方
Image-to-Imageとは、画像からプロンプトに沿った画像に変換する機能のことを言います。 Image-to-Imageを使うと、顔画像をアニメ化したり、ラフ画を具体化したりすることができます。
顔画像のアニメ化
Image-to-Imageを使うと、Meitsuのように自分の顔をアニメにすることができます。 img2imgのタブクリックして次の画面を開いてください。

例えば、次のような写真を用意します。

この写真は本機能のテストのために使ってもらって大丈夫です。 この目的であれば、SNS上に変換後の画像を公開しても、私は著作権や肖像権を行使しません。 なお、他の人の写真や絵に対してImage-to-Imageをかける行為は絶対しないでください。 著作権や肖像権を侵害するおそれがあります。
これを説明するプロンプトを作り、プロンプトの形式の描きたい内容として入力します。 プロンプトを考えるのがめんどくさい場合は、"Interrogate CLIP"ボタンを押してください。 ここではエヴァの画風にします。 Denoising strengthは0.5ぐらいがおすすめです。

prompt: anime, evangelion, a face of a man wearing a brown mask and black glasses in front of wooden wall, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
このようにエヴァに出てくるキャラっぽくなります。 他にもいろんなタイプや画風が試せます。次のは少女漫画っぽくする例とエルデンリングっぽくする例を紹介します。

prompt: manga, monochrome, black and white manga style, shoujo manga style, a face of a man wearing a white mask and black glasses in front of wooden wall, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text

prompt: game, ((elden ring)), a face of a man wearing a white mask and black glasses in front of wooden wall, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
顔写真だけではなく、いろんなものに試してみてください。
ラフ画の具体化

画像を入れてプロンプトを入力するとできます。
(後日詳細を伝えます。)
プロンプトの形式
ここでは、生成したいものに応じて、プロンプトの作り方を説明します。
キャラクター編
基本的には、ネガティブプロンプトにbad anatomyを全力でいれてください。 ネガティブプロンプトに
(((deformed))), blurry, ((((bad anatomy)))), bad pupil, disfigured, poorly drawn face, mutation, mutated, (extra limb), (ugly), (poorly drawn hands), bad hands, fused fingers, messy drawing, broken legs censor, low quality, (mutated hands and fingers:1.5), (long body :1.3), (mutation, poorly drawn :1.2), ((bad eyes)), ui, error, missing fingers, fused fingers, one hand with more than 5 fingers, one hand with less than 5 fingers, one hand with more than 5 digit, one hand with less than 5 digit, extra digit, fewer digits, fused digit, missing digit, bad digit, liquid digit, long body, uncoordinated body, unnatural body, lowres, jpeg artifacts, 2d, 3d, cg, text
を入れておけば、だいたい大丈夫だと思います。
キャラクターを表示するときに役立つカメラアングルとしては、portraitとfull bodyがあります。 キャラクターを横長に生成したい場合は、768x576 (4:3)の解像度で生成してください。 (Highreso. fixは不要です。)

prompt anime, a portrait of a girl with black short hair and red eyes wearing red kimono in a japanese shrine, from front side,, full color illustration, official art, 4k, detailed
negative prompt: (((deformed))), blurry, ((((bad anatomy)))), bad pupil, disfigured, poorly drawn face, mutation, mutated, (extra limb), (ugly), (poorly drawn hands), bad hands, fused fingers, messy drawing, broken legs censor, low quality, (mutated hands and fingers:1.5), (long body :1.3), (mutation, poorly drawn :1.2), ((bad eyes)), ui, error, missing fingers, fused fingers, one hand with more than 5 fingers, one hand with less than 5 fingers, one hand with more than 5 digit, one hand with less than 5 digit, extra digit, fewer digits, fused digit, missing digit, bad digit, liquid digit, long body, uncoordinated body, unnatural body, lowres, jpeg artifacts, 2d, 3d, cg, text
キャラクターを縦長に生成したい場合は、576x768 (3:4)の解像度で生成してください。

prompt: anime, a full body of a girl with black short hair and red eyes wearing red kimono standing neutrally, from front side, gray background, good anatomy, good hands, full color illustration, official art, 4k, detailed
negative prompt: (((deformed))), blurry, ((((bad anatomy)))), bad pupil, disfigured, poorly drawn face, mutation, mutated, (extra limb), (ugly), (poorly drawn hands), bad hands, fused fingers, messy drawing, broken legs censor, low quality, (mutated hands and fingers:1.5), (long body :1.3), (mutation, poorly drawn :1.2), ((bad eyes)), ui, error, missing fingers, fused fingers, one hand with more than 5 fingers, one hand with less than 5 fingers, one hand with more than 5 digit, one hand with less than 5 digit, extra digit, fewer digits, fused digit, missing digit, bad digit, liquid digit, long body, uncoordinated body, unnatural body, lowres, jpeg artifacts, 2d, 3d, cg, text
背景編
基本的には、ネガティブプロンプトにphotoを全力でいれてください。 ネガティブプロンプトに
(((deformed))), photo, people, girl, boy
を入れておけば、だいたい大丈夫だと思います。
背景を横長に生成したい場合は、768x576の解像度で生成してください。

prompt: anime, (shinkai makoto), mount fuji, official art, 4k, 8k, highly detailed
negative prompt: (((deformed))), photo, people, girl, boy
背景を縦長に生成したい場合は、576x768 (3:4)の解像度で生成してください。

prompt: anime, (shinkai makoto), Tokyo Sky Tree, 4k, 8k, highly detailed
negative prompt: (((deformed))), photo, people, girl, boy
ChatGPT編
一発ネタとして、プロンプトをChatGPTに考えさせることはできます。 例えば、このようにメガネを掛けた美少女のプロンプトを考えさせることができます。

このプロンプトを入力するとそれっぽいものが出てきます。なお、ネガティブプロンプトは別途入れてください。

prompt: Generate an image of a beautiful girl with glasses drawn in the style of Ilya Kuvshinov, as if she were a character in Evangelion.
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
ね、かんたんでしょ。
応用編
応用編として、東方シリーズのサウンドノベルの画面を雑に作ってみましょう。 シーンとしては博麗霊夢と霧雨魔理沙が会話しているシーンとしてみましょう。
まず、切り抜きやすいようにシンプルな背景で博麗霊夢を生成します。

prompt: game, touhou project, a portrait of a beautiful girl with back long hair on ((gray background)), hakurei reimu, touhou project official artwork, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
次に、切り抜きやすいようにシンプルな背景で霧雨魔理沙を生成します。

prompt: game, touhou project, a portrait of a beautiful girl on ((gray background)), kirisame marisa, touhou project official artwork, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
そして、それっぽい背景である神社を生成します。

prompt: anime, shinkai makoto style, makoto shinkai style, 神社 in japan, 4k, 8k, highly detailed
negative prompt: photo, people
最後にPhotoshopで合成します。

完成しました。所要時間は30分もかかっていないと思います。 本当は顔の大きさとか色々考えて調整したほうが良いと思います。
公開にあたってのメッセージ
クリエイターの方々へ
私は先日、新海誠監督の最新作『すずめの戸締まり』を見てきました。 あの映画を見るまでは心のなかで創作業界に対する心配でいっぱいでした。 しかし、その心配は不要だと感じました。 『すずめの戸締まり』ほど日本人の心を揺さぶる物語はChatGPTとStable Diffusionではまだできないと感じました。 日本の創作業界はStable Diffusionのようなおもちゃで敗れるそんなやわなものではないと思っています。 ただ、近い未来、AIに負けてしまう危険はあると思っています。 覚悟を持って今できる行動をとってください。
ユーザの方々へ
Stable Diffusionを始めとする拡散モデルは包丁と同じです。人を育てることをできれば、人を傷つけることもできます。 包丁はなんのために存在しているのかを考えてください。 ひとえに人を育てるために使われるのです。 拡散モデルも同じです。人を傷つけるために使う力ではありません。 拡散モデルは現代科学の結晶であり、大いなる力を宿しています。
大いなる力には大いなる責任が伴う
この言葉を理解できない人は拡散モデルそのものを使うべきではありません。 この言葉を常に胸に当て、この大いなる力を活用してください。
ノブレスオブリージュ。貴方が今後も救世主たらんことを
付録
プロンプトの形式詳細
- クールジャパンの種類: anime, manga, game
- 画風やフレーバーテキスト: google spreadsheet
- 描写したい内容: google spreadsheet
Cool Japan Diffusion 2.1.0 の取扱説明書

はじめに
本記事では、2023/1/3に公開する予定の画像生成AI、Cool Japan Diffusion (for learning) 2.1.0 の取り扱い方について説明します。 まず、インストール方法をざっくり説明します。 その後、使い方の説明、特にプロンプトのテンプレートを説明します。 最後に、クリエイターの方々へ、ユーザの方々へメッセージをお送りします。 なお、現在、Hugging Face上でデモを行っているので、そちらを使うのが楽です。
インストール方法
基本的には、Web UIを想定しています。 ほとんど、Cool Japan Diffusion for learning 2.0 と変わらないため、 こちらの記事を参考にすると良いかもしれません。
使い方
スマートフォン、またはパソコンからWeb UIのアドレスにアクセスしてください。 スマートフォンでは次のような画面が出てきます。

パソコンでは次のような画面が出てきます。
パソコンのほうが使いやすいので、以下は、パソコンの方で説明します。
Text-to-Imageの使い方
Text-to-Imageを使うと、文章から画像を生成することができます。この文章のことをプロンプトといいます。また、生成される画像の中に含まれてほしくない文章をネガティブプロンプトといいます。 Cool Japan Diffusionのプロンプト形式はNovel AI Diffusionなどとは全く違います。 これは研究用途以外には倫理的問題のあるデータセットであるDanbooruデータセットを含んでいないためです。 Cool Japan Diffusionのプロンプト形式は通常のStable Diffusionと同じものだと考えてください。このため、他のモデルやサービスと違って手軽さはありません。 一方で、基本的には形式に従って入力すれば、かんたんに出力することができます。 形式に従う必要はありませんが、手軽に楽しむためには形式をコピー・アンド・ペーストすることをおすすめします。
Cool Japan Diffusionでは、日本の文化、クールジャパンを(イラストを含む)アニメ、マンガ、ゲームの3種類で大まかに分類して生成することができます。 まず、それぞれの例を紹介します。

prompt: anime, ilya kuvshinov , (evangelion), a portrait of a girl with blue short hair and red eyes, ayanami rei, full color illustration, high quality fanart, artgerm, top rated on pixiv, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text

prompt: manga, black and white manga style, (rei hiroe black lagoon manga), a close up of a cool girl, official artwork, award winning manga style, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text

prompt: game, elden ring, close up of a dragon, concept art, 4k, 8k, highly detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
このようにプロンプトは長いですが、このプロンプトをベースに微妙に修正するだけでいろいろなバリエーションを生むことができます。
Cool Japan Diffusionのプロンプトは次のような形式をとっています。
クールジャパンの種類, 画風(作家名、作品名), 描写したい内容, フレーバーテキスト
これを先程のプロンプトに当てはめてみます。
anime(クールジャパンの種類), ilya kuvshinov , (evangelion), (画風)a portrait of a girl with blue short hair and red eyes,(描写したい内容) ayanami rei, full color illustration, high quality fanart, artgerm, top rated on pixiv, 4k, detailed(フレーバーテキスト)
大まかにはこのような形式でいろんな画像を生成できます。 付録に形式に使えるフレーズをまとめましたので、参考に使ってください。 ただし、作品名や作家名を入れた場合、著作権を侵害するおそれがあることから、2つ以上混ぜたりしてください。 作品名や作家名はチートコマンドのようなものだと思ってください。
Image-to-Imageの使い方
Image-to-Imageを使うと、Meitsuのように自分の顔をアニメにすることができます。 img2imgのタブクリックして次の画面を開いてください。
例えば、次のような写真を用意します。
この写真は本機能のテストのために使ってもらって大丈夫です。 この目的であれば、SNS上に変換後の画像を公開しても、私は著作権や肖像権を行使しません。 なお、他の人の写真や絵に対してImage-to-Imageをかける行為は絶対しないでください。 著作権や肖像権を侵害するおそれがあります。
これを説明するプロンプトを作り、プロンプトの形式の描きたい内容として入力します。 プロンプトを考えるのがめんどくさい場合は、"Interrogate CLIP"ボタンを押してください。 ここではエヴァの画風にします。 Denoising strengthは0.5ぐらいがおすすめです。
prompt: anime, evangelion, a face of a man wearing a brown mask and black glasses in front of wooden wall, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
このようにエヴァに出てくるキャラっぽくなります。 他にもいろんなタイプや画風が試せます。次のは少女漫画っぽくする例とエルデンリングっぽくする例を紹介します。
prompt: manga, monochrome, black and white manga style, shoujo manga style, a face of a man wearing a white mask and black glasses in front of wooden wall, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
prompt: game, ((elden ring)), a face of a man wearing a white mask and black glasses in front of wooden wall, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
顔写真だけではなく、いろんなものに試してみてください。
プロンプトの形式
ここでは、生成したいものに応じて、プロンプトの作り方を説明します。
キャラクター編
基本的には、ネガティブプロンプトにbad anatomyを全力でいれてください。 ネガティブプロンプトに
low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
を入れておけば、だいたい大丈夫だと思います。
キャラクターを表示するときに役立つカメラアングルとしては、portraitとfull bodyがあります。 キャラクターを横長に生成したい場合はHighres. fixをオンにして、768x512の改造で生成してください。

prompt anime, ilya kuvshinov, (evangelion), a portrait of a girl with black short hair and red eyes wearing red kimono, from front side, gray background, good anatomy, full color illustration, official art, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text, nsfw
キャラクターを縦長に生成したい場合はHighres. fixをオンにして、512x768の改造で生成してください。

prompt: anime, ilya kuvshinov , (evangelion), a full body of a girl with black short hair and red eyes wearing red kimono standing neutrally, from front side, gray background, good anatomy, good hands, full color illustration, official art, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text, nsfw
背景編
基本的には、ネガティブプロンプトにphoto, people, girl, boyを全力でいれてください。 ネガティブプロンプトに
photo, people, girl, boy
を入れておけば、だいたい大丈夫だと思います。
背景を横長に生成したい場合はHighres. fixをオンにして、768x512の改造で生成してください。

prompt: anime, (shinkai makoto), japanese shrine, official art, 4k, 8k, highly detailed
negative prompt: photo, people, girl, boy

prompt: anime, (shinkai makoto), mount fuji, official art, 4k, 8k, highly detailed
negative prompt: photo, people, girl, boy
背景を縦長に生成したい場合はHighres. fixをオンにして、512x768の改造で生成してください。

prompt: anime, (shinkai makoto), the great buddha, official art, 4k, 8k, highly detailed
negative prompt: photo, people, girl, boy
ChatGPT編
一発ネタとして、プロンプトをChatGPTに考えさせることはできます。 例えば、このようにメガネを掛けた美少女のプロンプトを考えさせることができます。
このプロンプトを入力するとそれっぽいものが出てきます。なお、ネガティブプロンプトは別途入れてください。
prompt: Generate an image of a beautiful girl with glasses drawn in the style of Ilya Kuvshinov, as if she were a character in Evangelion.
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
ね、かんたんでしょ。
応用編
応用編として、東方シリーズのサウンドノベルの画面を雑に作ってみましょう。 シーンとしては博麗霊夢と霧雨魔理沙が会話しているシーンとしてみましょう。
まず、切り抜きやすいようにシンプルな背景で博麗霊夢を生成します。
prompt: game, touhou project, a portrait of a beautiful girl with back long hair on ((gray background)), hakurei reimu, touhou project official artwork, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
次に、切り抜きやすいようにシンプルな背景で霧雨魔理沙を生成します。
prompt: game, touhou project, a portrait of a beautiful girl on ((gray background)), kirisame marisa, touhou project official artwork, 4k, detailed
negative prompt: low quality, bad face, ((((bad anatomy)))), ((bad hand)), lowres, jpeg artifacts, 2d, 3d, cg, text
そして、それっぽい背景である神社を生成します。
prompt: anime, shinkai makoto style, makoto shinkai style, 神社 in japan, 4k, 8k, highly detailed
negative prompt: photo, people
最後にPhotoshopで合成します。
完成しました。所要時間は30分もかかっていないと思います。 本当は顔の大きさとか色々考えて調整したほうが良いと思います。
公開にあたってのメッセージ
クリエイターの方々へ
私は先日、新海誠監督の最新作『すずめの戸締まり』を見てきました。 あの映画を見るまでは心のなかで創作業界に対する心配でいっぱいでした。 しかし、その心配は不要だと感じました。 『すずめの戸締まり』ほど日本人の心を揺さぶる物語はChatGPTとStable Diffusionではまだできないと感じました。 日本の創作業界はStable Diffusionのようなおもちゃで敗れるそんなやわなものではないと思っています。 ただ、近い未来、AIに負けてしまう危険はあると思っています。 覚悟を持って今できる行動をとってください。
ユーザの方々へ
Stable Diffusionを始めとする拡散モデルは包丁と同じです。人を育てることをできれば、人を傷つけることもできます。 包丁はなんのために存在しているのかを考えてください。 ひとえに人を育てるために使われるのです。 拡散モデルも同じです。人を傷つけるために使う力ではありません。 拡散モデルは現代科学の結晶であり、大いなる力を宿しています。
大いなる力には大いなる責任が伴う
この言葉を理解できない人は拡散モデルそのものを使うべきではありません。 この言葉を常に胸に当て、この大いなる力を活用してください。
ノブレスオブリージュ。貴方が今後も救世主たらんことを
付録
プロンプトの形式詳細
- クールジャパンの種類: anime, manga, game
- 画風やフレーバーテキスト: google spreadsheet
- 描写したい内容: google spreadsheet
今年の振り返りと、サンタの挑戦状

Happy Holidays!
あるふです。
投稿者の皆様、読者の皆様、アドベントカレンダー、お疲れ様でした。 今年のアドベントカレンダーは過去最高に波乱にみちたカオスが詰まっていて、素晴らしいと思います。
まずは、今年のアドベントカレンダーをざっくり振り返ってみます。
| 投稿日 | 投稿者の背景 | 概要 |
|---|---|---|
| 12/1 | AIの研究者 | 今年の振り返り |
| 12/2 | 匿名 | 画像生成AIに対する期待 |
| 12/3 | VTuber予定 | Dreamboothの結果 |
| 12/4 | AI開発者 | Clean Diffusion |
| 12/5 | ゲーム開発者 | 今後の予想 |
| 12/6 | AI漫画家 | AI漫画 |
| 12/7 | AI開発者 | Cool Japan Diffusion |
| 12/8 | 大学生 | AI絵で稼ぐ方法 |
| 12/9 | 闇のエンジニア | 雑誌の紹介 |
| 12/10 | AI開発者 | 学習用Cool Japan Diffusion |
| 12/11 | イラストレーター | 権利の問題 |
| 12/12 | アマチュア | 画像生成AIを使った感想 |
| 12/13 | VR関係 | 画像生成AIによる立体視 |
| 12/14 | 対話の研究者 | 定量的指標の紹介 |
| 12/15 | 画像の研究者 | デジタル贋作の紹介 |
| 12/16 | ゲーム開発者 | 画像生成AIによるゲーム画面のレンダリング |
| 12/17 | 統計の研究者 | Schedulerの自作 |
| 12/18 | アーティスト | 画像生成AIを使う人への言葉 |
| 12/19 | VR開発者 | VRアバターの作成 |
| 12/20 | 翻訳家? | 定量的指標の提案 |
| 12/21 | ディレクター | 生成AI全体の予想 |
| 12/22 | - | (まだ) |
| 12/23 | 小説家 | 画像生成AIによる挿絵 |
| 12/24 | 謎 | AIアートに対するメタ的分析 |
| 12/25 | AIアーティスト | サンタの挑戦状 |
このようにカラフルな背景のもとにいろんな意見が交わされました。今後も画像生成AIについて、活発で建設的な議論が交わされていくことを願っています。
さて、本来はここでクリスマスプレゼントとして、学習用Cool Japan Diffusion 2.1のモデルを配布する予定でした。ただ、反対の意見が多く見られるため、やめました。
そこで、クリスマスプレゼントとして挑戦状を皆様にお送りします。AIアートグランプリに投稿予定の作品を紹介します。 私が投稿する予定の作品は、「Cool Japan」というタイトルになる予定です。 私はインタラクションが専門の研究者なので、インタラクティブなメディア・アートでも良かったのですが、 審査員へ無意味に負担がかかると思い、やめました。普通に映像作品にします。 ざっくり内容を説明すると、平安時代から現代までの日本の芸術を振り返り、なぜ「Cool Japan」が生まれたのかを短い映像で語る内容になる予定です。時間がなくて作れない可能性もあります。 今の所、決まっていることとして、画像生成AI(Cool Japan Diffusionと学習用Cool Japan Diffusion 2.1)を用いて動画を作成し、楽曲として越天楽を使用する予定です。
学習用Cool Japan Diffusion 2.0の時点で学術的指標であるCLIP ScoreとFIDにて、公開されているモデルの中で現状よいとされていますが、2.1は比にならない出力だと考えてください。
みなさま、ぜひ、この作品を超えるアートを投稿してください。 アート界の藤井聡太はあなたかもしれません。
それでは良い年末を。
学習用Cool Japan Diffusionの紹介と公開するかについて

(prompt: manga, monochrome, a cute girl with long white hair in the coffee shop)
はじめに
今回、学習用Cool Japan Diffusionを紹介します。 どういう為のものなのか、どういうものなのか、どういうものが生成できるのかについて説明します。
学習用Cool Japan Diffusionの目的
このモデルは、Cool Japan DiffusionにStable Diffusionがもつ知識を与えるために作られています。 それというのも、Cool Japan DiffusionはStable Diffusionの派生モデルと違って、 ゼロベースで作られているカスケード型拡散モデルであるため、 まったく知識がありません。 このため、Stable Diffusionがもつ23億枚の知識のうち、よく使いそうなプロンプトや画像を抽出して、 再利用することをしています。 あえて、LAIONを使わないのは、LAIONがダウンロードするには多すぎることと著作権の問題があると判断したからです。 その点、Stable Diffusionの出力はCC-0であるため、著作権はなく、ある意味安心して使うことができます。 (本当か?)
学習用Cool Japan Diffusion 2.0の作り方
学習用Cool Japan Diffusion 2.0はStable Diffusion 2.0のVAEとU-Netを通常のファインチューニングで調整したモデルです。 イメージとしては、VAEは表現能力を司る機能、U-Netは概念を記憶する機能を持っています。 使用されている学習データは、主にTwitter APIにより取得した、Twitterに公開されている画像、20万枚程度です。 VAEにはこの20万枚程度の画像が学習されています。 このうち、9万枚はCLIP interrogatorにより、プロンプトがつけられています。 U-Netにはこの9万枚が学習に使用されています。
学習用Cool Japan Diffusion 2.0の生成例
今回は、プロンプト自動生成AIが勝手に出力していた白い長い髪の少女を題材に説明していきます。 まずは単なる「白い長い髪の少女」を生成してみました。

(prompt: a girl with long white hair)
あ、Stable Diffusionで出てくる微妙なイラストだとなります。 それでは、少し工夫してみましょう。Stable Diffusion では kawaii や moe を入れると、なんかアニメっぽくなります。 そこで、それらを入れてみると、こうなります。

(prompt: a kawaii girl with long white hair)

(prompt: a moe girl with long white hair)
なんかちょっとそれっぽくなりました。で、本題に入ると、フレーバーを付け加えるとこうなります。

(prompt: anime, a beautiful girl with long white hair, 4k, detailed)

(prompt: anime, a cute girl with long white hair, 4k, detailed)
なんか心がぴょんぴょんしそうなキャラが出てきましたね。 なんだかコーヒーが飲みたくなってきたので、カフェに行きましょう。

(prompt: anime, a cute girl with long white hair and blue eyes in the coffee shop, 4k, detailed)
カフェに行きました。しかし、キャラが違う気がします。 さて、このように背景を追加することもできますが、 これらをマンガ風にする事もできます。

(prompt: manga, monochrome, a cute girl with long white hair)

(prompt: manga, monochrome, a cute girl with long white hair in the coffee shop)
他のブログでも指摘がありましたが、たしかにあまり本モデルは背景には強くありません。 参考程度に背景に使えそうな生成画像を貼ります。

(prompt: mountains, fantasy, concept art, 4k, 8k, highly detailed)

(prompt: anime, buildings in Tokyo, concept art, 4k, detailed)

(prompt: anime, plains, concept art, 4k, detailed)

(prompt: anime, concept art, starry sky, 4k, detailed)
これもやはりマンガ風にできます。

(prompt: manga, monochrome, buildings in Tokyo, highly detailed)
また、同じく配布する予定のイラストに特化した超解像HAT-CC-0を使うことで印刷品質に上げることができます。


このように使うことができます。ただし、あくまで主目的はCool Japan Diffusionに知識を与えることなので、このモデル自体を人が使用することは想定されていません。
学習用Cool Japan Diffusionは人が使うことを想定していないモデルのため、悪用すると、デジタル贋作 (Digital Forgery) という現象 [1] を引き起こすことができます。 例えば、イリヤさんという人が描いた少女を生成しましょう。

(prompt: a painting of a girl with long white hair, 4k, detailed, by Ilya)
迫力のある少女が出てきましたね。では、とある名前を入れ、生成してみましょう。

(prompt: 非公開)
ところで、イリヤさんという攻殻機動隊などで有名なイラストレーターがいます。
— イリヤ・クブシノブ (@Kuvshinov_Ilya) 2022年11月10日
このような行為は、もし、人が触る場合やらないでほしいと願うばかりです。
学習用Cool Japan Diffusion 2.1の公開について
学習用Cool Japan Diffusion 2.1は2.0よりも遥かに強力になります。 VAEの学習用に60万種類以上使われる予定です。 なぜ枚じゃなく種類かというと、データ拡張と呼ばれる手法で無限に増やせるからです。 U-Netの学習用には30万枚以上使用される予定です。 これもデータ拡張で倍ぐらいには増やせます。
現在、Waifu Diffusionと呼ばれるアニメ・マンガ用に特化したStable Diffusionの派生モデルが公開される予定となっています。 これはイラスト版漫画村とも呼ばれる無断転載サイトDanbooruというサイトから取得されたデータ600万枚以上で作られています。 個人的には非常に問題があるモデルだと思っています。
このモデルを使用することは利用者のモラルを低下させると判断したため、 著作権法、および、刑法175条、各サイトの規約やガイドラインを考慮したモデルである学習用Cool Japan Diffusion 2.1を 公開し、こちらを使用してほしいと思っています。 ただ、それが日本の創作業界に悪影響を及ぼすと思うのであれば、 私に苦情を言ってください。 それらを加味して、公開を判断します。
よろしくおねがいします。
参考文献
[1] Gowthami Somepalli et al., "Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models" arXiv, 2022
Cool Japan Diffusionの開発体制

はじめに
今回はCool Japan Diffusionの開発体制を説明します。 ただし、あくまで表に出せる範囲でしか出しません。
Cool Japan Diffusionのマシンパワー(表側)
Cool Japan Diffusionは主に我が家のMAGIによって開発されています。

Cool Japan Diffusionの開発体制の概要図(矢印はデータの流れ)
MELCHIOR (メルキオール) : Cool Japan Diffusionの学習を担当する。
- GPU: RTX 4090 (実測上A100よりも速い) 、GTX 1080 (明日RTX 3060に替える予定)
- CPU: 第12世代Core i5
- メインメモリ: 128GB
- 不揮発性メモリ: 1TB
- ストレージ (SSD): 1TB
- ネットワーク: 2.5 GbE
BALTHASAR (バルタザール) : Cool Japan Diffusionの学習に使う画像のキャプション付けを担当する。(Clean Diffusionの開発も担当している。)
CASPER (カスパー) : Stable Diffusionを追加学習することで生成器を作成したり、学習用データを収集したりすることを担当する。
- GPU: RTX 3090、GTX 1660
- CPU: 第12世代Core i5
- メインメモリ: 64GB
- 不揮発性メモリ : 1TB
- ストレージ (SSD): 2TB
- ストレージ (HDD): 16TB
- ネットワーク: 2.5 GbE
ARTABAN (アルタバン) : ありとあらゆるデータを確実に保管し、各マシンに供給することを担当する。いわゆるNAS。
- ストレージ: 約20TB (RAID5、スナップショット付き。元々は32TB)
- ネットワーク: 2.5 GbE
MAGI以外にもクラウドで活躍しているインスタンスたちもいます。
illustrator (イラストレーター) : メルキオールでは対応しきれない学習を担当する。
- GPU: A100 x 1以上 (x2がコスパいいという仕事上の経験がある)
- CPU: 12 vCPU以上
- メインメモリ: 85GB以上
- ストレージ (SSHD): 100GB以上
- ストレージ (HDD): 1TB以上
generator n (生成器 n) : Stable Diffusionの知識を抽出するために画像を生成している。
- GPU: T4 x 1
MBA (MacBook Air) : 主に事務処理や裏側に接続することを担当している。
あとは裏側にもいます。これは秘密ですね。
Cool Japan Diffusionのデータ・リソース(表側)
Cool Japan Diffusionのデータ・リソースは倫理的な判断により自身でリミットを課しています。 基本的に絵画やイラスト、アニメ、漫画、ゲーム画面などが用意されています。
- パブリックドメインのデータ
- 無償公開されている違法ダウンロードではないインターネットのデータ、追加学習したStable Diffusionにより生成されたデータ
- 第一段階、第二段階を除く、情報解析として合法的に、かつ、倫理的に利用できるデータ
- その他、情報解析として合法的に利用できるデータ
- (おまけの画像)
現在、第2段階まで開放されています。現状は、合計1650万枚(おまけを入れると1億枚)以上で、各段階の枚数は次のとおりです。
- 200万枚以上
- 400万枚以上
- 250万枚以上
- 800万枚以上
- (8000万枚以上)
合計は第4段階までで1億枚以上まで増える予定です。特に第2, 3段階がもりもり増えていきます。 現状でも引っ張り出せばまだあると思いますが、把握しきれていません。
Cool Japan Diffusionの開発
Cool Japan Diffusionは、解明された拡散モデル [1] によるカスケードモデル [2] を採用しています。 このモデルを採用した画像生成AIはまだ見たことがありません。 おそらく現状の実用レベルではこれが限界だと思われます。
- 拡散モデルによる128x128 (超解像による512x512)
- 拡散モデルによる512x512 (超解像による2048x2048)
- 拡散モデルによる2048x2048 (超解像による8196x8196)
実用上は第2段階でサービス提供可能になります。 第1段階の出力は次のとおりです。

この細かさで第2段階は出力されます。 これが純粋な拡散モデルの力です。 1ピクセル1ピクセルで出力されるのです。 しかし、まだ学習途中なので、顔が崩れがちになっていますね。 また、現状超解像で次のとおりになります。
超解像のアルゴリズムとしてManga109データセットではSOTAであるHATを採用しています。 この手元にあるHATのモデルには上記のデータ・リソースがふんだんに使われており、 イラストに対しては現状最高性能の超解像だと自負しています。 このクオリティ程度で512x512 (2048x2048) でまずは提供する予定です。 超解像を含めて生成時間は20秒程度です。 期待に答えられるようにがんばります。
Cool Japan Diffusionの課題
マシンパワーが足りていません。あとクラウドがあんまり割り当ててくれません。 H100の登場が待ち遠しいです。マシンパワーをください。
以上です。
参考文献
[1] Tero Karras et al., "Elucidating the Design Space of Diffusion-Based Generative Models," NeurIPS 2022
[2] Chitwan Saharia et al., "Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding," NeurIPS 2022
Clean Diffusionの紹介
 題名:『文明開花・序』(この画像はパブリックドメインと加工自由な画像から作られています。
アルゴリズムはClean Diffusionと異なり、Imagenを用いています。)
題名:『文明開花・序』(この画像はパブリックドメインと加工自由な画像から作られています。
アルゴリズムはClean Diffusionと異なり、Imagenを用いています。)
はじめに
今年、Stable Diffusionなどの画像生成AIが突然流行った結果、社会が混乱しました。具体的には、たかだか数ヶ月の間に 研究フェーズから実用フェーズへと移行し、倫理や法的整備も全く追いつかないままに 芸術の分野に雷鳴のごとく画像生成AIは現れました。 その結果、人々は画像生成AIに対する倫理や価値観に混乱しました。 その混乱の原因の一つに、 画像生成AIは他人の著作物を一方的に学習して、真似をできてしまう ことがあります。 そのことは 著作権者の利益を不当に害すること に繋がりかねません。 これを理由として、自分の画風をコピーさせるサービスmimic (β)の提供や CLIP STUDIO PAINTへの画像生成AI搭載は一旦見送られることになりました。 画像生成AIにより画風をコピーできる技術の研究をしていた私も、正直悪用する方法しか思いつかず、 かなり何ヶ月も悩んでいました。
そこで、一方的に学習しても真似しても問題ない他人の著作物を使って画像生成AIを作れば、 社会の混乱を抑えられるのではないかと考えました。 その著作物とは、 パブリックドメイン (CC-0) の著作物 です。 パブリックドメインの著作物は著作権が切れており、自由に使用することができます。 このため、パブリックドメイン (CC-0) の著作物を用いた画像生成AIは著作権を侵害する可能性は非常に低いとの見解を 柿沼弁護士から伺いました。
今回は私が開発しているパブリックドメインのみでできた、著作権者の利益を不当に害する可能性がほぼない画像生成AI、Clean Diffusionを紹介します。 Clean Diffusionはまだ開発途中なので、構想と途中経過の紹介になってしまいます。予めご了承ください。
Clean Diffusionの概要
Clean DiffusionはStable Diffusionと全く同じ構造でできています。 Stable Diffusionと異なるのは学習データがパブリックドメインであることだけです。 したがって、具体的なアルゴリズムはStable Diffusionについて調べてください。
Clean Diffusionのメリットは著作権者の利益を不当に害する可能性がほぼないことがまず挙げられます。 したがって、商用利用しても限りなく0に近いぐらい問題はありません。後ろめたいことは全くありません。 その他にもStable Diffusionの環境で利用できること、Stable Diffusionの改造方法がそのまま利用できることが挙げられます。
Clean DiffusionのデメリットはStable Diffusionよりも表現力が非常に低いことです。 Stable Diffusionは23億枚学習に使われているのに対して、Clean Diffusionは現状7万枚しかありません。 したがって、改造に使うことは前提として考えてもらえれば、幸いです。 また、パブリックドメインの性質上、カラー写真が著しく少なく、カラーの実写に近い画像は作れない問題があります。
Clean Diffusionの現状
現在、国際版Clean Diffusionを開発しています。
Clean Diffusionは2段階ある学習のうち1段階をクリアした状態であり、2段階目をクリアする途中にあります。 Clean Diffusionの1段階目は画像を圧縮するところ、2段階目は画像を生成するところになります。 1段階目は画像を情報圧縮するところを検査するには、入力画像を圧縮し、展開する作業が一致するかどうかを見ることがあります。 以下の図は1段階目の学習初期になります。

学習初期の入力画像

学習初期に入力画像を圧縮し、展開したところ
学習初期には全く学習できていないことがわかります。 しかし、現状では次の通り、しっかり圧縮し、展開できていることがわかります。

学習中期の入力画像

学習中期に入力画像を圧縮し、展開したところ
したがって、それなりに画像を圧縮できることがわかりました。
一方で、2段階目をクリアする途中であり、調整が意外と難しい気がしています。 例えば、"A girl."の出力は現状この様になっています。

なんか油のインクを塗りたくったような絵が出ましたね。 まだ、うまく概念を学べていないのだと思います。 それというのも今やり直している最中であり、まだ学習して2日目なのです。 まともなものを出すには、おそらく1週間はかかります。
この2段階目の画像を見てしまうと、そもそも7万枚で本当に画像生成AIが作れるのかという疑問がわきます。 しかし、最初のアイキャッチに使っている画像は、アルゴリズムは異なりますが、 ほぼこの7万枚から作られています。したがって、Clean Diffusionもおそらく作れるだろうと考えています。
Clean Diffusionの予定
国際版Clean Diffusionは非常に表現能力が低いものになるでしょう。 しかし、パブリックドメインの定義は国によって異なるため、日本に絞れば、実は学習画像を増やし、表現能力を向上させられます。 現在、日本版Clean Diffusionの開発のために、約200万枚程度の画像を用意しています。先程の7万枚とは2桁も違います。 例えば、この中にはふしぎの国のアリスやローマの休日などがあります。 ふしぎの国のアリスなどはパブリックドメインであるとされており、ローマの休日は司法がパブリックドメインであると判断しています。 このように国際版Clean Diffusionはあまり期待はしてもらっても困りますが、日本版はそれなりの表現能力は出せるように努力します。